- Sidecar pattern: Each application instance has a Sidecar container in the same network namespace (for example, the same Kubernetes Pod), and sends gRPC requests to it locally.
- Standalone service: The Sidecar runs as a shared service that multiple applications can access over an exposed port within your private network.

Sidecar running with in-memory cache
- In-memory cache (default): managed directly by the Sidecar
- Redis cache: managed together with a Persistent Cache Service
- The Sidecar uses an in-memory LRU cache capped by size.
- You can control the cache size with the
CACHE_MAX_SIZE_BYTESenvironment variable. - If not set, the Sidecar allocates up to
50%of the total available memory for the cache. - When scaled horizontally with in-memory cache only, you may see a higher cache-miss ratio because each instance maintains its own cache.
- On a cache miss, the Sidecar fetches data from the Stigg API and updates the cache before serving future requests.
- Only entitlements and current usage are cached. Subscriptions are not part of it.
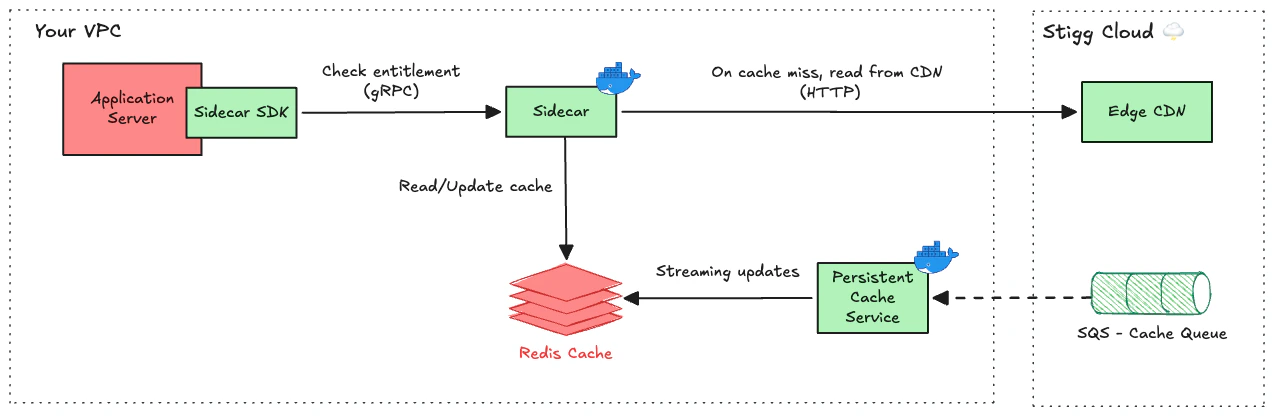
Sidecar running with an external Redis cache
- You run in serverless environments (for example, AWS Lambda) where processes are frequently terminated
- You have a large fleet of containers and want fresh entitlements and usage available immediately when new instances start
- You want cached entitlements and usage to survive restarts and be shared across instances